
|
Usama Fayyad
Technical Group Supervisor Machine Learning Systems Group Jet Propulsion Laboratory California Institute of Technology Pasadena, CA 91109 U.S.A. fayyad@aig.jpl.nasa.gov tel: (818) 306-6197, fax: (818) 306-6912 |
Evangelos Simoudis
Director, Data Mining Solutions IBM Research Almaden Research Center 650 Harry Rd. San Jose, CA 95120-6099 Simoudis@almaden.ibm.com |
Hosted By
Department of Computer Science
University College, The University of New South Wales
Australian Defence Force Academy, Canberra, ACT 2600, Australia
Last modified Wed Oct 4 12:09:14 1995
Knowledge Discovery in Databases is a new AI field that has received much attention from the AI community. The increased interest on KDD is attested by the success of one IJCAI and three AAAI workshops, two books (one already published and another to appear in August: Advances in Knowledge Discovery and Data Mining ), and the success of a tutorial on the topic delivered by the proposers in the Avignon '94 conference and to be delivered at IJCAI-95 in August. The interest in and growth of this field has culminated in changing the format of previous workshops to an open conference format: The First International Conference on Knowledge Discovery and Data Mining (KDD-95) In addition, several government organizations such as the NSF, and NASA are now sponsoring research in this field, and an increasing number of KDD-related dissertations and publications have begun to appear.
KDD has matured rapidly. Various industrial research AI laboratories, such as those at IBM, GTE, Lockheed, AT&T, and GM are now supporting KDD projects. In addition, companies such as Hecht Nielsen, Reduct, and Lockheed are already marketing KDD systems.
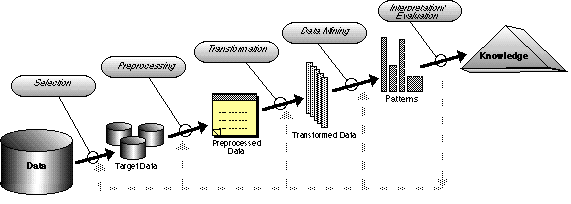
Knowledge Discovery in Databases (KDD) is an emerging field that combines techniques from machine learning, pattern recognition, statistics, Databases, and visualization to automatically extract concepts, concept interrelations, and patterns of interest from large databases. The basic task is to extract knowledge (or information) from lower level data (databases). The basic tools used to extract patterns from data are called Data Mining methods, while the process of surrounding the usage of these tools (including pre-processing, selection, and transformation od the data) and the interpretation of patterns into ``knowledge'' is the KDD process. This extracted knowledge is subsequently used to support human decision-making, e.g., prediction and classification tasks, summarize the contents of databases, or explain observed phenomena. The use of KDD systems alleviates the problem of manually analyzing the large amounts of collected data which decision-makers face currently. KDD systems have been implemented and currently in use in finance, fraud detection, market data analysis, astronomy, diagnosis, manufacturing, and biology. Problems in KDD include representation of the extracted knowledge, search complexity, the use of prior knowledge to improve the discovery process, controling the discovery operation, statistical inference, and selecting the most appropriate data mining method(s) to apply on a particular data set.
Capabilities offered by KDD are becoming extremely important today as the amounts of the data collected in various fields such as biology, finance, retail, etc. increases, while our ability to analyze that data has not kept up proportionately.
This tutorial program presents a comprehensive picture of current research paradigms in the field of Data Mining and Knowledge Discovery in Databases (KDD) and a synthesis of KDD's fundamental issues, techniques and contributions to AI. Initially, the tutorial will provide an accessible, overall introduction to KDD. Next, we will present methods for data preparation and preprocessing. We then provide a detailed description of major data mining techniques from the fields of AI, pattern recognition, and statistics. Techniques from databases, and visualization are presented in context of KDD. Finally, we describe applications of KDD systems on real problems of data analysis. In the process, the tutorial addresses such issues as:
The objective of the tutorial is to present the mechanisms and techniques underlying Knowledge Discovery in Databases (KDD) with emphasis on KDD's potential as an alternative to current data analysis and expert system building techniques for the development of applications. KDD addresses several AI issues such as how to identify the most appropriate of the extracted knowledge, and how to best represent this knowledge, how to control the search for the most valuable knowledge, and how to select the most appropriate data mining technique(s) to apply on a particular data set. Since the data mining step is central to the KDD process, we provide coverage of some of the algorithms available for data mining (namely, extracting patterns from data).
The tutorial will explore both theoretical and practical issues. It will (1) identify the features of each KDD technique that make it applicable to a particular data set and analysis goal, (2) characterize application domains where KDD has shown excellent results, and others where KDD appears to be promising, and (3) identify problems with the existing KDD methods, and outline areas where additional research must be performed.
As the authors of KDD systems that have been applied on a variety of fields and as educators who have taught about KDD in the classroom and previous tutorials, we have created a tutorial program that presents both a comprehensive picture of the field's varied current paradigms and a synthesis of KDD's fundamental issues, techniques and contributions to AI. Specifically, the tutorial has been designed to:
This tutorial is intended for (a) professionals interested in current KDD research issues including data analysts, and researchers from various data intensive fields, (b) managers and decision-makers interested in sophisticated methods for data analysis, (c) engineers considering developing KDD applications, and (d) researchers or students interested in gaining broad coverage of this important emerging area. There are no special prerequisites for the tutorial although some experience with data analysis of any type, or familiarity with basic AI concepts and approaches to representing knowledge and controlling inference will be helpful. The tutorial will emphasize important concepts in KDD and illustrate them by working through accessible examples. The tutorial will not deal with low level programming or implementation and does not presume any knowledge of a particular programming language or data analysis program.
Usama M. Fayyad, Jet Propulsion Laboratory, California Institute of Technology
Usama Fayyad is Technical Group Supervisor of the Machine Learning Systems Group at the Jet Propulsion Laboratory, California Institute of Technology. He is also an adjunct assistant professor in the CS Dept. at USC. At JPL, he is Principal Investigator of the Science Data Analysis and Visualization Task targeting applications of data mining techniques for the analysis of large science databases, as well as other tasks involving industrial applications of machine learning. He received the Ph.D. degree in Computer Science and Engineering in 1991 from the EECS Department of The University of Michigan, Ann Arbor. He holds the following degrees: B.S.E. in E.E., B.S.E. and M.S.E. in Computer Engin., and M.Sc. in Mathematics. He is a recepient of the 1993 Lew Allen Award for Excellence, the highest honor JPL awards to researchers in the early years of their professional careers. He has also received the NASA Exceptional Achievement Medal (1994). His research interests include machine learning theory and applications, knowledge discovery in large databases, neural networks, and non-linear regression. He served on the program committees of several conferences in AI including AAAI-93, ML-93+95, TAI-93. He has co-chaired the Eleventh SPIE Applications of AI Conference (1993), and the 1994 Knowledge Discovery in Databases Workshop at AAAI-94. He is co-chair of the First International Conference on Knowedge Discovery and Data Mining (KDD-95), and co-editor of the book: "Advances in Knowledge Discovery and Data Mining", published by AAAI/MIT Press (1995).
Evangelos Simoudis, IBM Almaden Research Center
Evangelos Simoudis is the Director of Data Mining Solutions, in IBM North America. Prior to joining IBM Dr. Simoudis worked at Lockheed where he and his team developed the Recon data mining system, and led research on knowledge discovery in databases, machine learning, case-based reasoning and their application to financial, retail, and fraud detection problems. In 1994 Dr. Simoudis and his team were awarded the Lockheed Pursuit of Excellence Award for their work on the Recon system. Simoudis is also an adjunt assistant professor at the Computer Engineering department of the Santa Clara University where he teaches graduate courses on machine learning and case-based reasoning. Dr. Simoudis holds a Ph.D. in Computer Science from Brandeis University, and M.S. in Computer Science from the University of Oregon, a B.S. in Electrical Engineering from the California Institute of Technology, and a B.A. in Physics from Grinnell College. Prior to joining Lockheed, Dr. Simoudis was a principal software engineer at Digital Equipment Corporation's Artificial Intelligence Center where he led work on case-based reasoning, learning, and distributed AI. Dr. Simoudis has written extensively on data mining, and case-based reasoning, and is the North American Editor of the Artificial Intelligence Review, associate editor of two other journals, and in the program and organizing committees of several technical conferences.